从"写报告"到"能签字":可靠性工作到底卡在哪
从"写报告"到"能签字":可靠性工作到底卡在哪
凌晨两点,你终于把那份可靠性评估报告写完了。
术语准确、逻辑顺畅、排版漂亮。你甚至觉得,这是这季度写得最好的一份。
第二天评审会,总工翻了两页,抬头问了一句:"这个失效率的结论,依据是哪份数据?"
你说不上来。报告是你用通用 AI 辅助写的——它读起来像那么回事,但你确实不知道那些数字是从哪条记录、哪个版本里来的。
这种感觉并非个例。恰恰相反,它是当下可靠性工程里最普遍的"应用落差"。
上一回我们说到:对现成 AI 不满意,问题往往不在模型够不够大。今天把镜头拉近一点——同一批问卷里,有一组数字放在一起读,像一把剪刀。
年初我们做了结构化收集,66 道题,有效样本约900+。在已经用过 AI 的同行里,最常见的用法并不是你想象的专业建模,而是一件更朴素的事:报告/文档撰写,占到约四成(多选口径)。
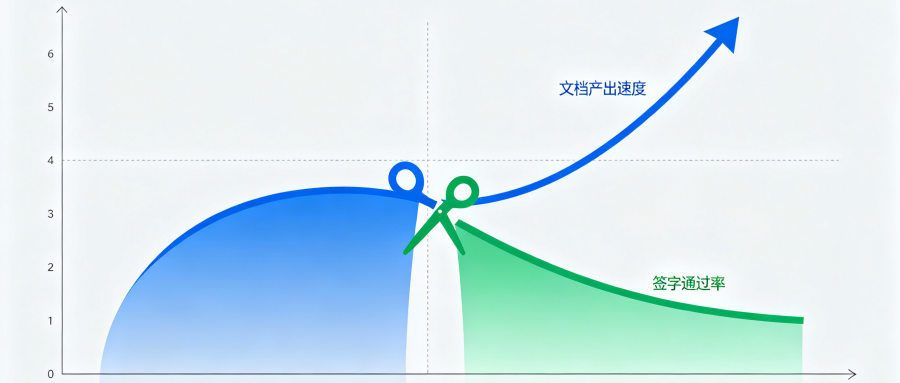
与此同时,大家最希望 AI 帮忙的业务是什么?排在前列的是 FMEA 智能分析与填写、故障诊断与预测性维护、试验方案优化——每一项单独看都不算小众,合在一起指向同一句话:大家想让 AI 往里走,走到表格里、走到试验数据和失效链条里。
一边是"写得多"——先把周报、说明、段落排版搞定;一边是"想得深"——最好能把 FMEA、诊断、试验几件事一起扛起来。两道弧线没有对上,就出现了剪刀差:写得越快,并不代表签得越干脆;排版越漂亮,也不代表依据已经对齐到你们家的那张表。
一、"会用AI"的第一站,常常是文档站
我们把问卷里"已用 AI 的场景"摊开看一眼:报告/文档撰写占比最高;其次是 FMEA 分析辅助;再往后才是诊断、统计、FTA/RBD 等。这和一线体感很像:门槛最低、见效最快的路,往往是先把文字打磨得像"行业口吻"。
但"像"不等于"对"。
通用AI工具最擅长的,是把公开发表的表述方式学到手。它并不能自动把你企业失效库里的那条备注、去年改过一次的打分表头、客户单独约定的判定口径一并带到段落里。写到第三屏还没出事,不等于写到签字页还能站得住脚。
二、期待那头,早就指向专业场景

同一份问卷里,当问到"最希望 AI 辅助哪些业务",FMEA 类与故障诊断/预测等方向合计占到需求清单里很显眼的一块。
换句话说:大家心里那张愿望单,从一开始就不是"再帮我润色两千字"。
可愿望单和今天的用法之间,偏偏隔着三件事——还是问卷里那份"主要痛点":数据积累不足难建模、分析方法复杂人手不够、工具不顺手——三项合计超过八成(多选累计口径)。
翻译成人话:不是不想深用,是材料还没在地上码齐、人还没腾出手、软件还没把专业路径铺顺——这时候最容易退回到"至少先把报告写出来",剪刀差就这样被越剪越大。
三、签字慢,到底慢在哪里
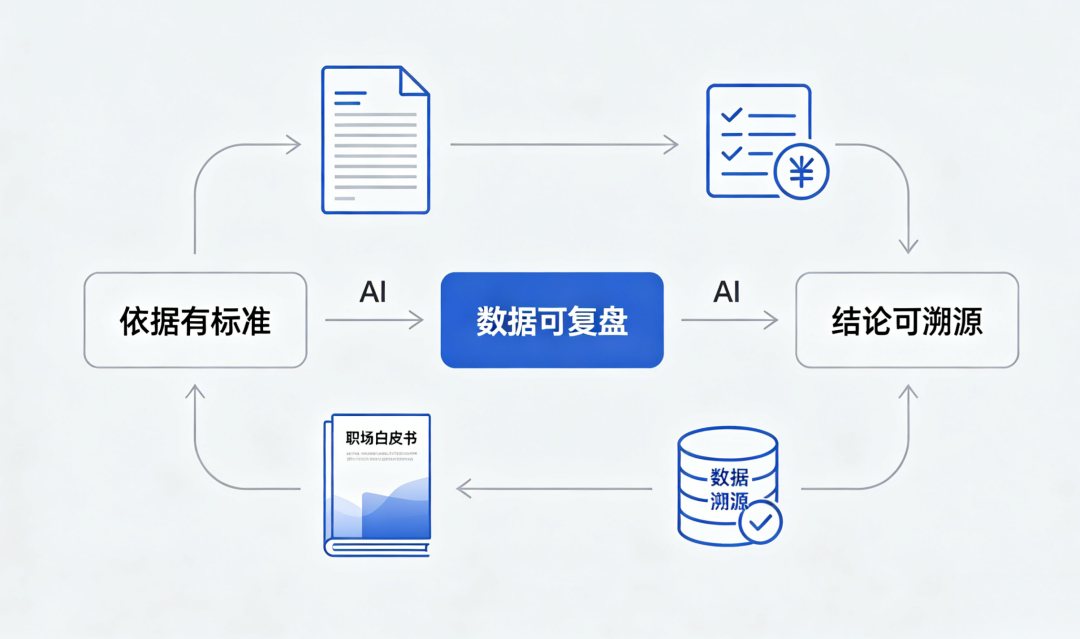
评审其实只问三件事:
1.依据有标准
你的结论,对得上哪条内部规定、哪张模板?
2.数据可复盘
你的数字,按什么算法来,别人能否复现?
3.结论可溯源
你的判断,最终能翻出哪份原始记录、哪个版本?
通用 AI 能把第零步做得很顺滑:把语气写得更像"可靠性工程师"。但从第一步开始,它就缺东西——缺你家条款、缺你家数据、缺可追溯的引用。
于是签字页上那个名字,仍然只能你自己扛。
所以我们会重复那句听起来很土的判断:可靠性不是比谁写得更像论文,而是比谁能在复盘时把链路说圆。 模型再热,也只是链条上的一环;缺了依据与复核,再华丽也只是"写完了",不是"能交代"。
四、我们做的事,其实不花哨
国可工软在 ReliaBuddy 上打的算盘并不复杂:先把资料登记与可追溯检索、把该算就算清楚、把没依据不冒充来源这几件事放进同一套桌面工作台里,再一段段把 FMEA、FTA、寿命分析这些专业化交付做厚。
与其推销"更聪明的模型",我们更愿意陪你磨"更经得起追问的那张纸"。
我们想做的,就是让"依据在哪"这个问题,在报告生成时就有答案,而不必等到评审会的凌晨。
相关文章
问卷里的三座山:数据、人、工具
同一份问卷揭示了可靠性工作者的三座大山:数据积累不足难以建模(约三成)、人员能力不足(约四分之一)、工具软件缺乏不好用(约四分之一)。三座山叠加覆盖率超过八成——不是哪家企业倒霉,而是样本中反复出现的结构性卡顿。ReliaBuddy 选择先修路:把本机资料可登记、可检索、能指认出处的每一步踏实走。
我们来晚了:AI 做 FMEA,别只写得好看,要能签字
FMEA 终审会上,最致命的一句追问是"依据在哪"。通用 AI 写得漂亮,但说不出依据——它不懂你们公司标准第几版、不知道探测度表头改过什么规则、接不上产线失效数据。ReliaBuddy 从三条断裂出发,用笨功夫填坑:知识能挂住引用、数据用算不用猜、没依据就认。
想了解更多或申请软件试用?
专业团队提供一对一解答,定制适合您的解决方案